hologres_sql_optimization
🗓️ 03022025 1110
Basic principles
ABSTRACT
Reduce I/O resource consumption and optimize concurrency
Configuring appropriate indexes
- If you configure appropriate indexes for data distribution when you create a table, the data that you want to query can be quickly located after an SQL statement is executed
- This reduces I/O and computing resource consumption and accelerates queries
- Balanced data distribution also helps increase the utilization of concurrent resources and prevent single-node bottlenecks
- The following figure shows the execution process from executing an SQL statement to obtaining data
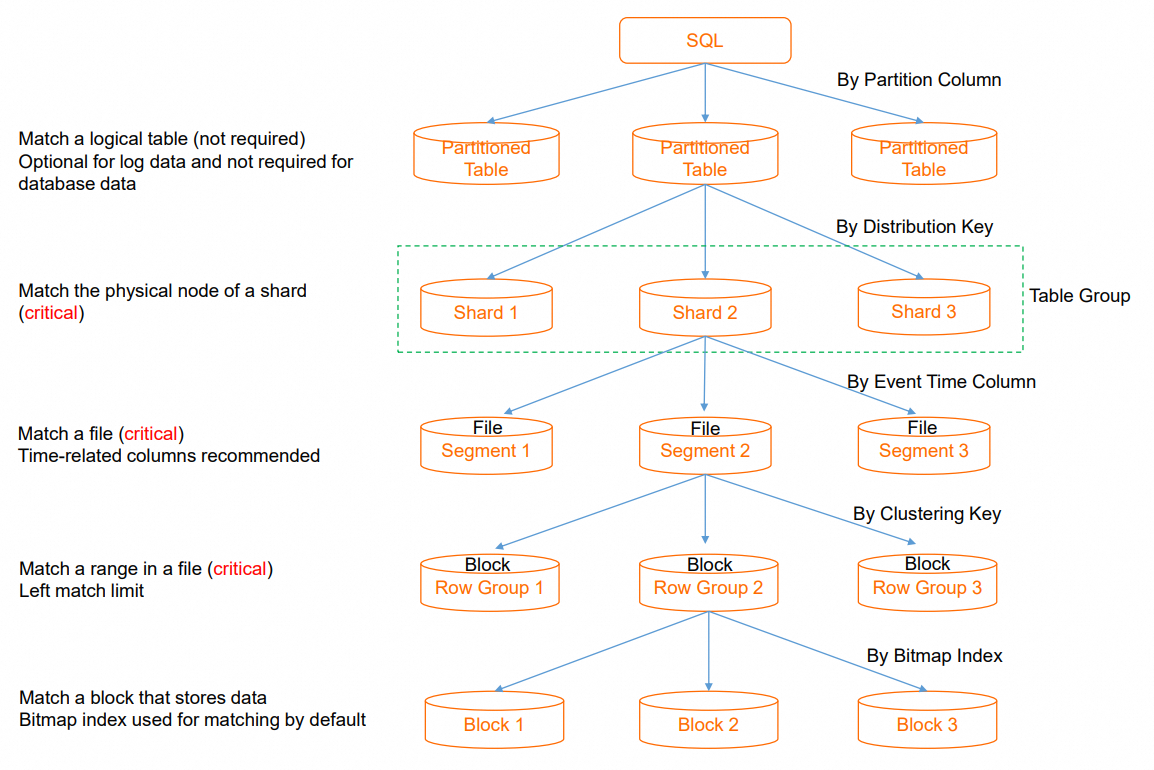
Partition pruning
- If you perform an SQL query on a partitioned table, the system locates the partition in which the required data is located by using the partition pruning feature
- If no partition is matched based on query conditions, the system needs to traverse all partitions, which consumes excessive I/O resources
- In most cases, partitioning by day is more appropriate
- For a non-partitioned table, partition pruning is not involved
hologres_shard pruning
- You can use a hologres_distribution_key to quickly locate the shard in which the desired data is located
- This reduces the resources that are required by a single SQL statement and supports a high throughput if multiple SQL statements are executed at the same time
- If the specific shard cannot be located, the system schedules all shards for computing based on the distributed framework
- In this case, a single SQL statement is executed on multiple shards, which consumes a large amount of resources and decreases the overall concurrency of the system
- Extra shuffle overhead is incurred if specific operators are executed in a centralized manner
- In most cases, you can configure fields whose values are evenly distributed as distribution key fields, such as the order ID, user ID, and event ID fields
- We recommend that you configure the same distribution key for the tables that you want to join to allow correlative data to be distributed to the same shard
- This helps achieve high efficiency in local join operations
hologres_segment_key pruning
- You can use an event time column to quickly locate the file in which the required data is located from multiple files on a node
- This eliminates the need to access other files
- If the filtering fails, the system needs to traverse all files
hologres_clustering_key pruning
- You can use the clustering key to quickly locate the desired data range in a file
- This helps improve the efficiency of range queries and field sorting