🗓️ 03112024 1135
📎 #flink
flink_training
ABSTRACT
- How to implement streaming data processing pipelines and why Flink manages state
- How to use event time to consistently compute accurate analytics
- How to build event-driven applications on continuous streams
- How Flink is able to provide fault-tolerant, stateful stream processing with exactly-once semantics
Stream processing
| Paradigm | Description |
|---|---|
| Batch Processing | For processing a bounded data stream |
| Stream Processing | Processing a unbounded data stream (input might never end) |
Flink applications composed of:
- Streaming data sources (message_queue)
- Operators - for transforming data
- Send result streams to sinks (applications that need this data)
Parallel dataflows
INFO
Programs in flink are inherently parallel and distributed

- During execution, a stream has one or more stream partitions
- Each operator has one or more operator subtasks
- The operator subtasks are independent of one another
- Execute in different threads / machines or containers
IMPORTANT
The number of operator subtasks is the parallelism of that particular operator
Transporting data between operators
One-to-one forwarding
Preserves partitioning / ordering of elements
Redistributing streams
- Changes partitioning of streams
- Ordering is preserved within each pair of sending / receiving subtasks
- Each operator subtask sends data to different target subtasks, depending on the selected transformation
- Examples
keyBy()broadcast()rebalance()
Timely Stream Processing
TLDR
Consider the timestamp at which the event happened rather than when the event was received
Stateful Stream Processing
ABSTRACT
Flink’s operations can be stateful > How one event is handled can depend on the accumulated effect of all the events that came before it
State is managed locally on each parallel instance either on
- JVM Heap
- On-Disk data structures (if memory too large)
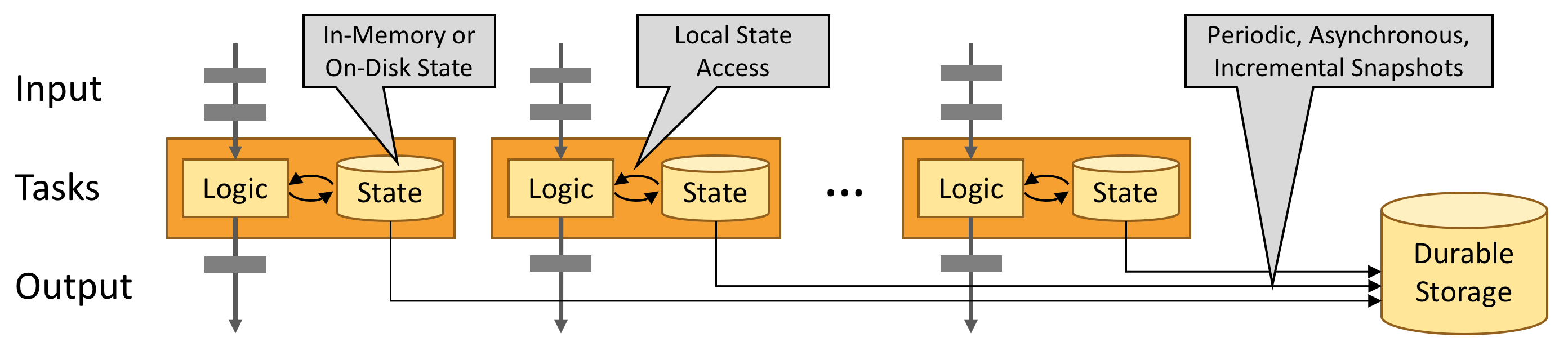
Fault Tolerance via State Snapshots
- Flink is able to provide fault-tolerant, exactly-once semantics through a combination of state snapshots and stream replay
Snapshots
- Capture entire state of the distributed pipeline asynchronously
- Offsets into input queues
- State throughout the job graph (up to the point of data ingestion)
Failure
- Sources are rewound
- State is restored
- Processing resumes