🗓️ 03022025 1106
When to use
- GROUP BY / JOIN operations frequently performed
- Prevent data_skew
The distribution key helps evenly distribute data on compute nodes
This significantly improves computing and query performance
Introduction
- Use
distribution_keyto specify distribution policy - Entries with same
distribution_keydistributed to same shard
-- Syntax supported in Hologres V2.1 and later
CREATE TABLE <table_name> (...) WITH (distribution_key = '[<columnName>[,...]]');
-- Syntax supported in all Hologres versions
BEGIN;
CREATE TABLE <table_name> (...);
call set_table_property('<table_name>', 'distribution_key', '[<columnName>[,...]]');
COMMIT;
| Parameter | Description |
|---|---|
| table_name | The name of the table for which you want to specify the distribution key. |
| columnName | The name of the column that you want to specify as the distribution key. |
Effects
Improved computing performance
- Parallel computing can be performed on different shards
- This improves computing performance
Improved queries per second (QPS)
- Can filter data based on the
distribution_key - Filter set: Hologres scans data only in the shards that meet filter conditions
- Filter not set: Hologres performs computing on all shards
Decreases the QPS
Improved join efficiency
- Hologres can perform local join operations when tables belong to the same table group and share the same distribution key
- This means the join is executed within the same segment (shard)
- Eliminates the need for costly data shuffling or transfers across the networ
This greatly improves execution efficiency
Usage notes
Rules for specifying a distribution key
-
Specify the columns in which data is evenly distributed as distribution key columns
- Otherwise, data skew issues may occur due to uneven allocation of computing resources > Reduces query efficiency
- Read Query the shard allocation among workers for troubleshooting data skew issues
-
Specify the columns on which the
GROUP BYoperation is frequently performed as distribution key columns.- In scenarios where you want to create and join tables, specify the join columns as the distribution key columns of the tables
- This way, the system can implement a local join, which helps prevent data shuffling
- The tables that you want to join must belong to the same table group
-
Recommended to specify no more than two columns as distribution key columns for a table
- If any of the distribution key columns is not hit during queries, data shuffling may occur
-
You can specify one column as a distribution key or more columns to constitute a distribution key
- Single column:
- Do not include extra spaces in the statement that you execute to specify the distribution key
- Multiple columns:
- Separate the columns with commas (,) and do not include extra spaces in the statement
- Order of the columns does not affect data layout and query performance
- Single column:
-
After you specify a primary key for a table, the distribution key must be the same as the primary key or a subset of the primary key
- For a table with a primary key, a distribution key is required because entries with the same distribution key value must be distributed to the same shard
- If you do not specify a distribution key, the primary key is used as the distribution key by default
Limits
- Distribution key can only be specified during table creation
- If you want to modify the distribution key for an existing table, you must create another table and import data to the table
- Cannot modify values of distribution key columns
- If you want to modify the values, you must create another table.
- Columns of the following data types cannot be specified as distribution key columns
- FLOAT
- DOUBLE
- NUMERIC
- ARRAY
- JSON
- Other complex data types ??? Whut
- For a table without a primary key, you can determine whether to specify a distribution key based on your business requirements
- If you do not specify a distribution key, data is randomly distributed to different shards
- In Hologres V1.3.28 and later, a distribution key must be specified, and the following sample statement is forbidden:
- For a distribution key column,
nullvalue is regarded as an empty string- Displayed as double quotation marks
(“”) - It indicates that no distribution key is specified.
- Displayed as double quotation marks
How it works
Specify a distribution key
-
data in the table is distributed to shards based on the distribution key by using the
Hash(distribution_key)%shard_countalgorithm -
The returned result is the shard ID
-
Entries with the same distribution key value are distributed to the same shard
-- Specify Column a as a distribution key column. Hologres performs a hash operation on the values in Column a and performs a modulo operation on the results. The returned result is the shard ID. Entries with the same distribution key value are distributed to the same shard.
CREATE TABLE tbl (
a int NOT NULL,
b text NOT NULL
)
WITH (
distribution_key = 'a'
);
-- Specify Column a and Column b as distribution key columns. Hologres performs a hash operation on the values in Column a and Column b and performs a modulo operation on the results. The returned result is the shard ID. Entries with the same distribution key value are distributed to the same shard.
CREATE TABLE tbl (
a int NOT NULL,
b text NOT NULL
)
WITH (
distribution_key = 'a,b'
); -
Syntax supported in all Hologres versions:
-- Specify Column a as a distribution key column. Hologres performs a hash operation on the values in Column a and performs a modulo operation on the hash results. The returned result is the shard ID. Entries with the same distribution key value are distributed to the same shard.
begin;
create table tbl (
a int not null,
b text not null
);
call set_table_property('tbl', 'distribution_key', 'a');
commit;
-- Specify Columns a and b to constitute a distribution key. Hologres performs a hash operation on the values in Columns a and b and performs a modulo operation on the hash results. The returned result is the shard ID. Entries with the same distribution key value are distributed to the same shard.
begin;
create table tbl (
a int not null,
b text not null
);
call set_table_property('tbl', 'distribution_key', 'a,b');
commit;
The following figure shows the data distribution.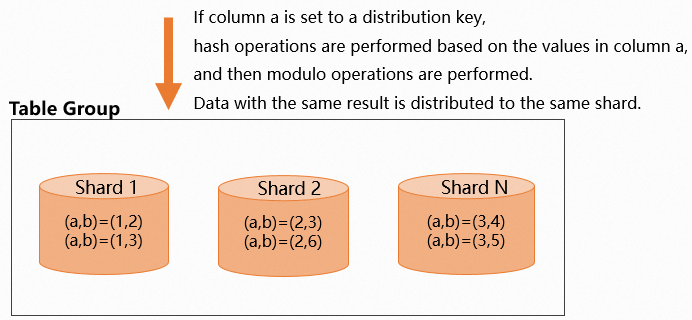 If you specify a distribution key, make sure that the data of the distribution key columns is evenly distributed. The shard count in Hologres is proportional to the number of worker nodes. For more information, see Basic concepts. If you specify columns in which data is unevenly distributed as distribution key columns, data is distributed to some shards and most computing resources are consumed by some worker nodes. As a result, long tails occur. alibabacloud.com/help/en/hologres/user-guide/query-the-shard-allocation-among-workers#task-2255914).
If you specify a distribution key, make sure that the data of the distribution key columns is evenly distributed. The shard count in Hologres is proportional to the number of worker nodes. For more information, see Basic concepts. If you specify columns in which data is unevenly distributed as distribution key columns, data is distributed to some shards and most computing resources are consumed by some worker nodes. As a result, long tails occur. alibabacloud.com/help/en/hologres/user-guide/query-the-shard-allocation-among-workers#task-2255914).
Do not specify a distribution key
If you do not specify a distribution key, data is randomly distributed to shards. The entries with the same value may be distributed to different shards. Examples:
-- Do not specify a distribution key.
begin;
create table tbl (
a int not null,
b text not null
);
commit;
The following figure shows the data distribution.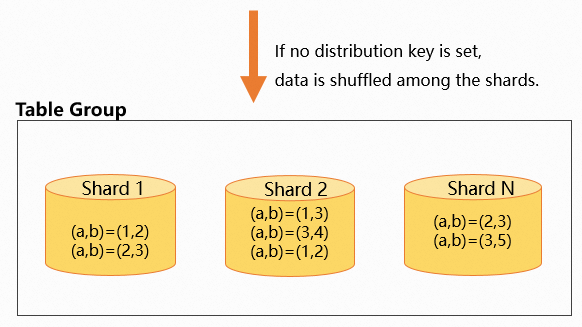
Specify a distribution key for a table on which the GROUP BY operation is frequently performed
After you specify a distribution key for a table, the entries with the same distribution key value are distributed to the same shard. If the GROUP BY operation is performed, the data is redistributed based on the specified distribution key during computing. You can specify the columns on which the GROUP BY operation is frequently performed as distribution key columns. In this case, the same data in the same shard is aggregated. This reduces data redistribution among the shards and improves query performance. Examples:
-
Syntax supported in Hologres V2.1 and later:
CREATE TABLE agg_tbl (
a int NOT NULL,
b int NOT NULL
)
WITH (
distribution_key = 'a'
);
-- Perform an aggregate query on Column a:
select a,sum(b) from agg_tbl group by a; -
Syntax supported in all Hologres versions:
begin;
create table agg_tbl (
a int not null,
b int not null
);
call set_table_property('agg_tbl', 'distribution_key', 'a');
commit;
-- Perform an aggregate query on Column a:
select a,sum(b) from agg_tbl group by a;
You can query the execution plan by executing the Explain statement. The following figure shows that the execution plan does not contain the redistribution operator. This indicates that no data is redistributed.
Specify distribution keys for two tables that you want to join
-
Specify both join columns as distribution keys.
If the join columns of the two tables are specified as distribution keys for the tables, the entries with the same distribution key value are distributed to the same shard. This way, a local join operation can be performed to join the two tables. This accelerates data queries. Examples:
-
Execute the following DDL statements to create two tables:
-
Syntax supported in Hologres V2.1 and later:
-- Data in the table named tbl1 is distributed based on Column a, whereas data in the table named tbl2 is distributed based on Column c. If you join the two tables by using the a=c condition, the matched data in the two tables is distributed to the same shard. This way, a local join operation is performed on the tables to accelerate data queries.
BEGIN;
CREATE TABLE tbl1 (
a int NOT NULL,
b text NOT NULL
)
WITH (
distribution_key = 'a'
);
CREATE TABLE tbl2 (
c int NOT NULL,
d text NOT NULL
)
WITH (
distribution_key = 'c'
);
COMMIT; -
Syntax supported in all Hologres versions:
-- Data in the table named tbl1 is distributed based on Column a, whereas data in the table named tbl2 is distributed based on Column c. If you join the two tables by using the a=c condition, the matched data in the two tables is distributed to the same shard. This way, a local join operation is performed on the tables to accelerate data queries.
begin;
create table tbl1(
a int not null,
b text not null
);
call set_table_property('tbl1', 'distribution_key', 'a');
create table tbl2(
c int not null,
d text not null
);
call set_table_property('tbl2', 'distribution_key', 'c');
commit;
-
-
Execute the following statement to join the tables:
select * from tbl1 join tbl2 on tbl1.a=tbl2.c;
The following figure shows the data distribution.
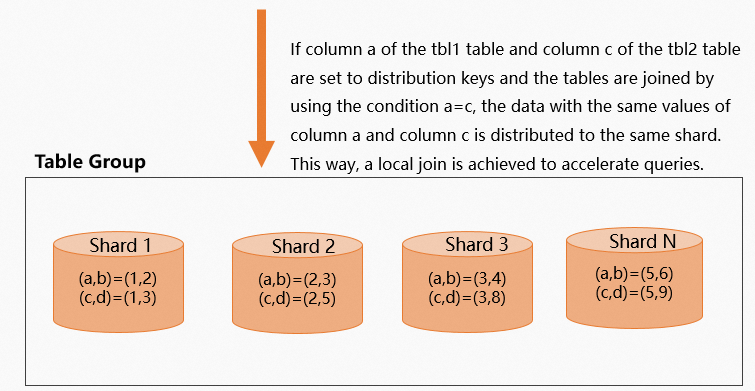 You can query the execution plan by executing the Explain statement. The following figure shows that the execution plan does not contain the
You can query the execution plan by executing the Explain statement. The following figure shows that the execution plan does not contain the redistributionoperator. This indicates that no data is redistributed.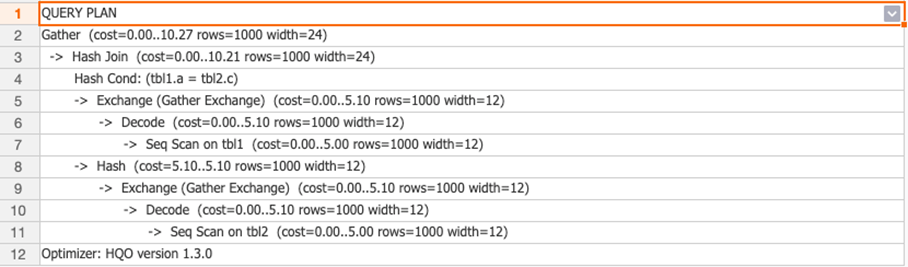
-
-
Specify only one of the join columns as a distribution key.
If one of the join columns of the two tables is not specified as a distribution key, Hologres shuffles data among different shards during queries. Hologres determines whether to shuffle or broadcast the data based on the size of the two tables that you want to join. In this example, Column
aof the table namedtbl1is specified as a distribution key, and Columndof the table namedtbl2is specified as another distribution key. If you join the tbl1 table and the tbl2 table by using thea=ccondition, Hologres shuffles the data in Columncin each shard. This reduces query efficiency.-
Execute the following DDL statements to create two tables:
-
Syntax supported in Hologres V2.1 and later:
BEGIN;
CREATE TABLE tbl1 (
a int NOT NULL,
b text NOT NULL
)
WITH (
distribution_key = 'a'
);
CREATE TABLE tbl2 (
c int NOT NULL,
d text NOT NULL
)
WITH (
distribution_key = 'd'
);
COMMIT; -
Syntax supported in all Hologres versions:
begin;
create table tbl1(
a int not null,
b text not null
);
call set_table_property('tbl1', 'distribution_key', 'a');
create table tbl2(
c int not null,
d text not null
);
call set_table_property('tbl2', 'distribution_key', 'd');
commit;
-
-
Execute the following statement to join the tables:
select * from tbl1 join tbl2 on tbl1.a=tbl2.c;
The following figure shows the data distribution.
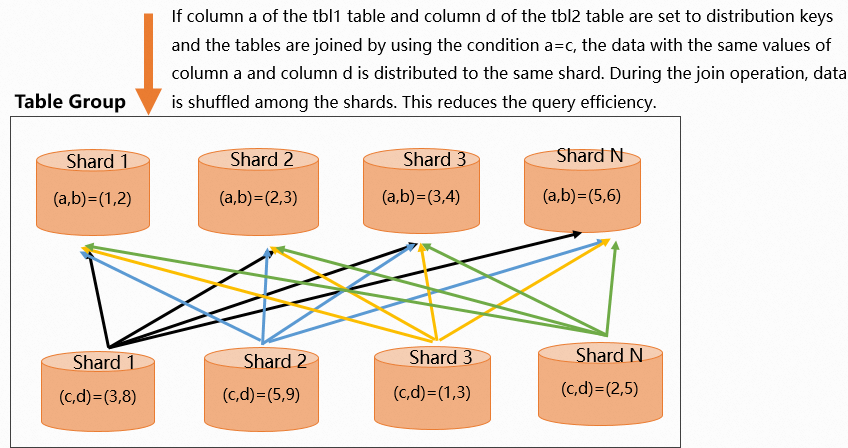 You can query the execution plan by executing the Explain statement. The following figure shows that the execution plan contains the
You can query the execution plan by executing the Explain statement. The following figure shows that the execution plan contains the redistributionoperator. This indicates that data is redistributed. The distribution key setting is inappropriate. You must modify the distribution key.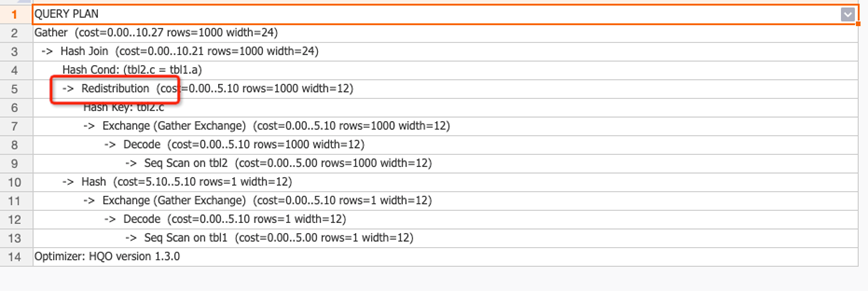
-
Specify distribution keys for multiple tables that you want to join
Take note of the following rules when you join multiple tables:
-
If the join columns of the tables are the same, you can specify these columns as distribution keys.
-
If the join columns of the tables are different, you can specify the join columns of the large tables as distribution keys.
In the following examples, three tables are joined. If you want to join more than three tables, use one of the following examples as a reference:
-
The join columns of the three tables are the same.
If the join columns of the three tables are the same, you can specify these columns as distribution keys to implement a local join. This scenario is the simplest scenario.
-
Syntax supported in Hologres V2.1 and later:
BEGIN;
CREATE TABLE join_tbl1 (
a int NOT NULL,
b text NOT NULL
)
WITH (
distribution_key = 'a'
);
CREATE TABLE join_tbl2 (
a int NOT NULL,
d text NOT NULL,
e text NOT NULL
)
WITH (
distribution_key = 'a'
);
CREATE TABLE join_tbl3 (
a int NOT NULL,
e text NOT NULL,
f text NOT NULL,
g text NOT NULL
)
WITH (
distribution_key = 'a'
);
COMMIT;
-- Execute the following statement to join the three tables:
SELECT * FROM join_tbl1
INNER JOIN join_tbl2 ON join_tbl2.a = join_tbl1.a
INNER JOIN join_tbl3 ON join_tbl2.a = join_tbl3.a; -
Syntax supported in all Hologres versions:
begin;
create table join_tbl1(
a int not null,
b text not null
);
call set_table_property('join_tbl1', 'distribution_key', 'a');
create table join_tbl2(
a int not null,
d text not null,
e text not null
);
call set_table_property('join_tbl2', 'distribution_key', 'a');
create table join_tbl3(
a int not null,
e text not null,
f text not null,
g text not null
);
call set_table_property('join_tbl3', 'distribution_key', 'a');
commit;
-- Execute the following statement to join the three tables:
SELECT * FROM join_tbl1
INNER JOIN join_tbl2 ON join_tbl2.a = join_tbl1.a
INNER JOIN join_tbl3 ON join_tbl2.a = join_tbl3.a;
You can query the execution plan by executing the Explain statement.
-
The
redistributionoperator is not included in the execution plan. This indicates that no data is redistributed and that a local join operation is performed. -
The
exchangeoperator indicates a shift from file-level aggregation to shard-level aggregation. In this case, only data in the corresponding shard is aggregated. This improves data query efficiency.
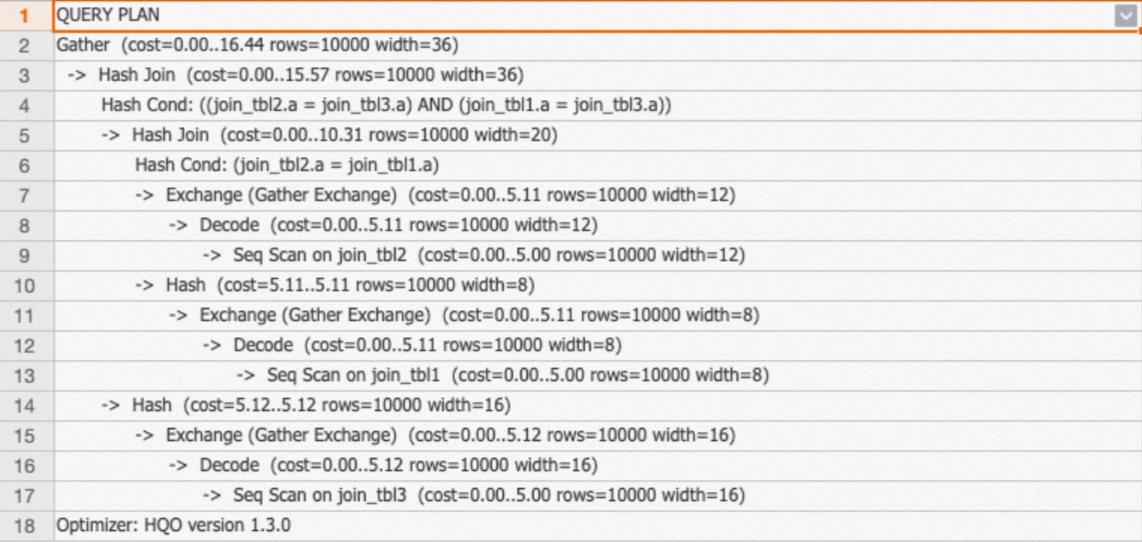
-
-
The join columns of the three tables are different.
In actual business scenarios, if you want to join multiple tables, the join columns may be different. In this case, take note of the following rules when you specify a distribution key:
-
Compared with small tables, large tables have a higher priority because small tables contain only a small amount of data. You can preferentially specify the join columns of the large tables as distribution keys.
-
If the amount of data in the tables is nearly the same, specify columns on which the GROUP BY operation is frequently performed as distribution keys.
In the following example, three tables named join_tbl_1, join_tbl_2, and join_tbl_3 are to be joined, and the join columns are not exactly the same. In this case, specify the join columns of the large tables as distribution keys. The
join_tbl_1table contains 10 million data entries. Both thejoin_tbl_2table and thejoin_tbl_3table contain one million data entries. Use thejoin_tbl_1table as the main optimization object.-
Syntax supported in Hologres V2.1 and later:
BEGIN;
-- The join_tbl_1 table contains 10 million data entries.
CREATE TABLE join_tbl_1 (
a int NOT NULL,
b text NOT NULL
)
WITH (
distribution_key = 'a'
);
-- The join_tbl_2 table contains one million data entries.
CREATE TABLE join_tbl_2 (
a int NOT NULL,
d text NOT NULL,
e text NOT NULL
)
WITH (
distribution_key = 'a'
);
-- The join_tbl_3 table contains one million data entries.
CREATE TABLE join_tbl_3 (
a int NOT NULL,
e text NOT NULL,
f text NOT NULL,
g text NOT NULL
);
WITH (
distribution_key = 'a'
);
COMMIT;
-- If the join columns of the tables that you want to join are different, specify the join columns of the large tables as distribution keys.
SELECT * FROM join_tbl_1
INNER JOIN join_tbl_2 ON join_tbl_2.a = join_tbl_1.a
INNER JOIN join_tbl_3 ON join_tbl_2.d = join_tbl_3.f; -
Syntax supported in all Hologres versions:
begin;
-- The join_tbl_1 table contains 10 million data entries.
create table join_tbl_1(
a int not null,
b text not null
);
call set_table_property('join_tbl_1', 'distribution_key', 'a');
-- The join_tbl_2 table contains one million data entries.
create table join_tbl_2(
a int not null,
d text not null,
e text not null
);
call set_table_property('join_tbl_2', 'distribution_key', 'a');
--The join_tbl_3 table contains one million data entries.
create table join_tbl_3(
a int not null,
e text not null,
f text not null,
g text not null
);
--call set_table_property('join_tbl_3', 'distribution_key', 'a');
commit;
-- If the join keys of tables that you want to join together are not the same, select the join keys of the large tables as distribution keys.
SELECT * FROM join_tbl_1
INNER JOIN join_tbl_2 ON join_tbl_2.a = join_tbl_1.a
INNER JOIN join_tbl_3 ON join_tbl_2.d = join_tbl_3.f;
You can query the execution plan by executing the Explain statement.
-
The
redistributionoperator is used for the computing of thejoin_tbl_2table and thejoin_tbl_3table. Thejoin_tbl_3table is a small table, and the join column of the small table is different from the distribution key. Therefore, the data is redistributed. -
No
redistributionoperator is used for the computing of thejoin_tbl_1table and thejoin_tbl_2table. The join columns of the two tables are specified as the distribution keys. Therefore, the data is not redistributed.

-
Examples
-
Syntax supported in Hologres V2.1 and later:
-- Specify a single column as a distribution key.
CREATE TABLE tbl (
a int NOT NULL,
b text NOT NULL
)
WITH (
distribution_key = 'a'
);
-- Specify multiple columns to constitute a distribution key.
CREATE TABLE tbl (
a int NOT NULL,
b text NOT NULL
)
WITH (
distribution_key = 'a,b'
);
-- In scenarios where multiple tables are joined, specify join columns as distribution keys.
BEGIN;
CREATE TABLE tbl1 (
a int NOT NULL,
b text NOT NULL
)
WITH (
distribution_key = 'a'
);
CREATE TABLE tbl2 (
c int NOT NULL,
d text NOT NULL
)
WITH (
distribution_key = 'c'
);
COMMIT;
SELECT b, count(*) FROM tbl1 JOIN tbl2 ON tbl1.a = tbl2.c GROUP BY b; -
Syntax supported in all Hologres versions:
-- Specify a single column as a distribution key.
begin;
create table tbl (a int not null, b text not null);
call set_table_property('tbl', 'distribution_key', 'a');
commit;
-- Specify multiple columns to constitute a distribution key.
begin;
create table tbl (a int not null, b text not null);
call set_table_property('tbl', 'distribution_key', 'a,b');
commit;
-- In scenarios where multiple tables are joined, specify join columns as distribution keys.
begin;
create table tbl1(a int not null, b text not null);
call set_table_property('tbl1', 'distribution_key', 'a');
create table tbl2(c int not null, d text not null);
call set_table_property('tbl2', 'distribution_key', 'c');
commit;
select b, count(*) from tbl1 join tbl2 on tbl1.a = tbl2.c group by b;
References
-
For more information about how to configure table properties based on business query scenarios, see Guide on scenario-specific table creation and tuning.
-
For more information about how to optimize the performance of queries on Hologres internal tables, see Optimize performance of queries on Hologres internal tables.
-
For more information about the DDL statements for Hologres internal tables, see the following topics: